CS 202 - Notes 2018-10-17
x86-64 Assembly
Data Formats
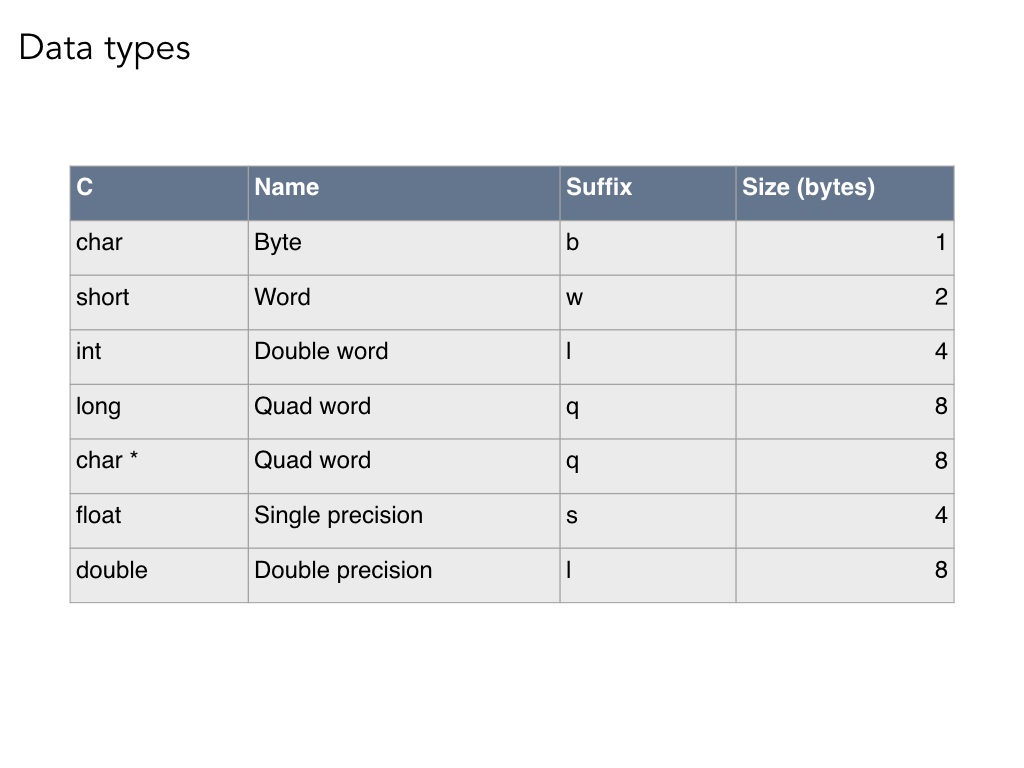
We only sort of have data types in assembly. The suffixes above are added onto instructions to tell the instruction how large a chunk of data it is working on. So, for example, if an instruction has a 'q' on the end, we know it will work on 64-bit data.
Registers
We have 16 64-bit registers.
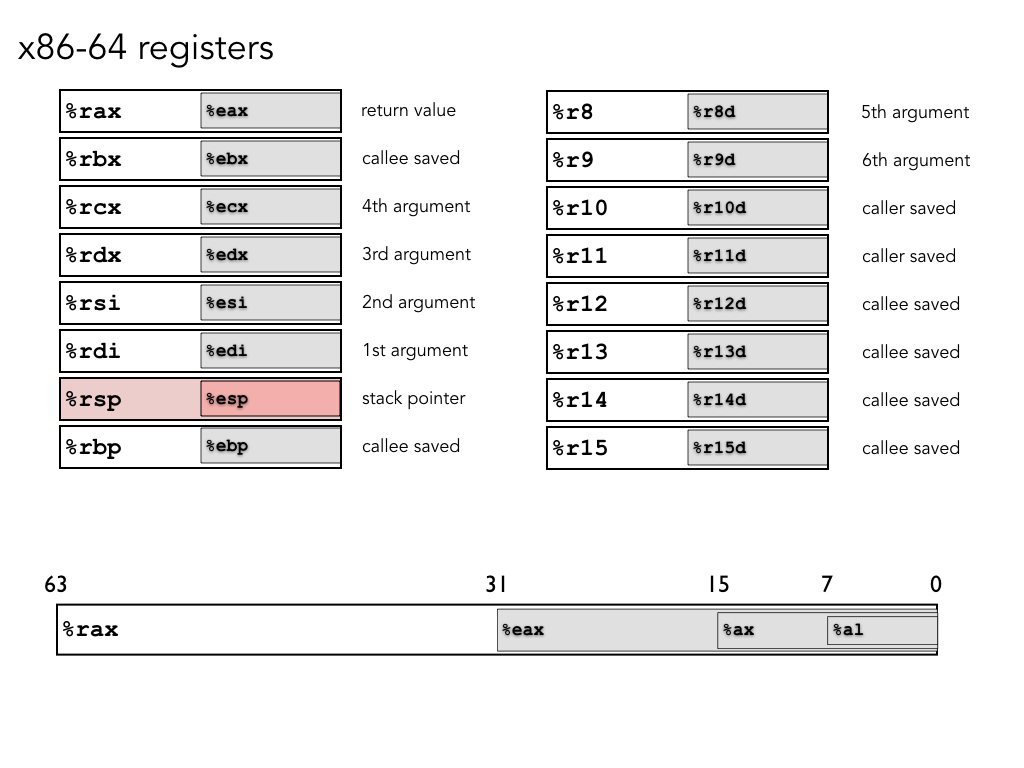
Each register can be dealt with as containing a 64,32,16,or 8 bit value depending on the name you use (e.g., %rax gives you all 64 bits, while %eax gives you the lower 32).
At one time they all had specific roles, which is somewhat reflected in their names. As we go, we will learn about the remaining roles and rules of use.
Operands
Operands to assembly instructions can be immediate (actual values), register (read from the register file), or memory (read out of memory).
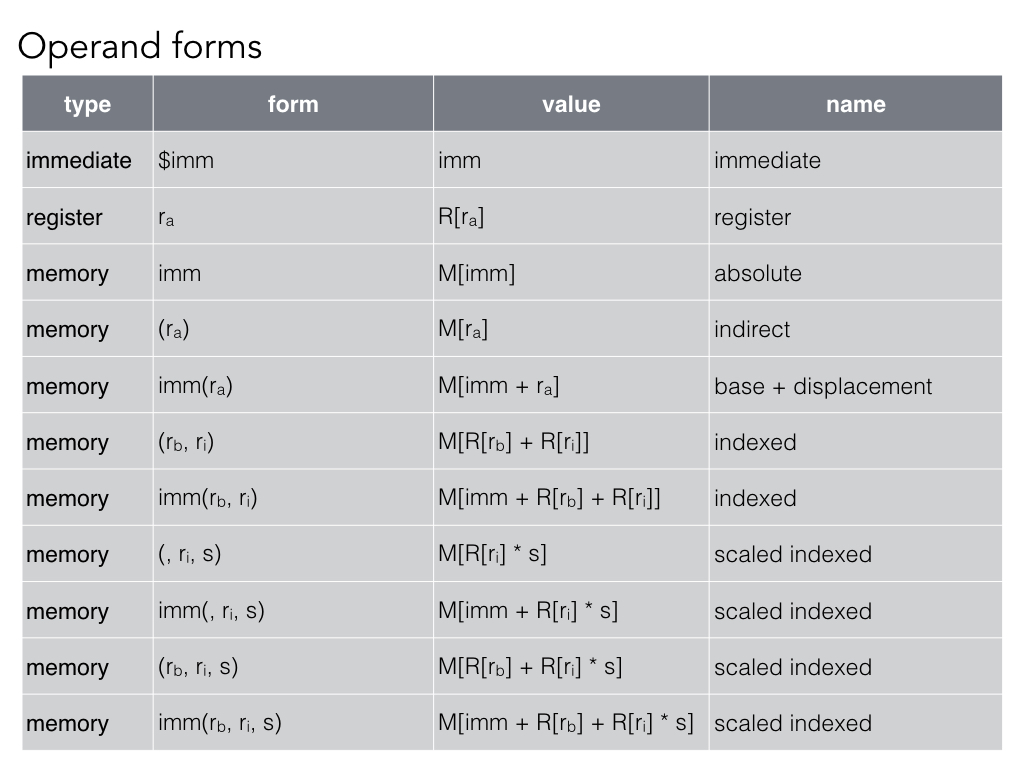
The most important of the memory address schemes to remember is the scaled and indexed with displacement format (imm(Rb, Ri, s)), which is the most general form. All of the others are merely variants of it with one or more of the arguments missing.
Arithmetic
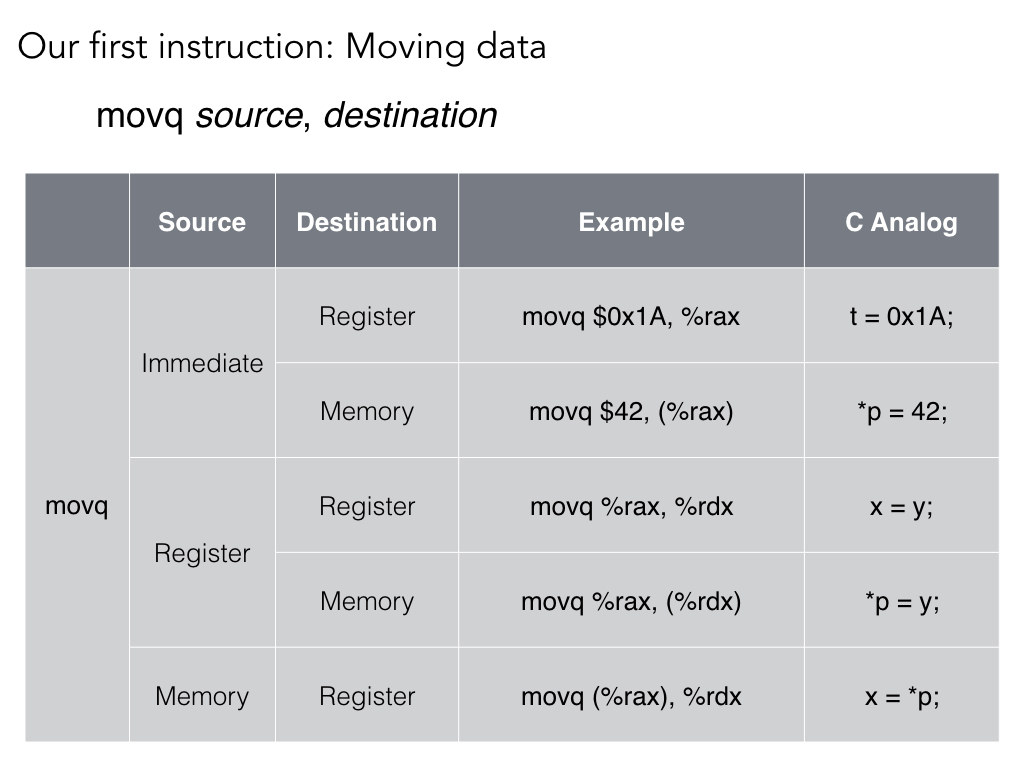
Mostly, these are what you would expect.
The lea instruction is an interesting one. The main purpose of the instruction is to compute memory addresses without the accompanying memory access. You will see it in a lot of generated assembly, because it can be used to quickly add numbers together using the faster address computation hardware.
Example
We looked at a very simple piece of code.
sum.c
int simple(int x, int y){
int sum = x + y;
return sum;
}
We compiled it (`gcc -S sum.c) and found this:
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
movl %edi, -20(%rbp)
movl %esi, -24(%rbp)
movl -20(%rbp), %edx
movl -24(%rbp), %eax
addl %edx, %eax
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
popq %rbp
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size simple, .-simple
.ident "GCC: (GNU) 7.2.1 20170915 (Red Hat 7.2.1-2)"
.section .note.GNU-stack,"",@progbits
We talked about the different levels of optimization, which is specified with the -O flag. The default is -O0, or no optimization. A more interesting level is -Og, which performs some optimization, but not so much that it would interfere with debugging.
After gcc -S sum.c -Og
.file "sum.c"
.text
.globl simple
.type simple, @function
simple:
.LFB0:
.cfi_startproc
leal (%rdi,%rsi), %eax
ret
.cfi_endproc
.LFE0:
.size simple, .-simple
.ident "GCC: (GNU) 7.2.1 20170915 (Red Hat 7.2.1-2)"
.section .note.GNU-stack,"",@progbits
We can see that this has optimized the code down to two lines. The first one uses leal to add together %rdi and %rsi and store the result in %eax. If you look at the list of registers, you wll see that %rdi and %rsi and argument 1 and argument 2 of the function (so x and y respectively). %eax is the return register. So, this added together the two arguments, put the result in the return register and then returned.