Closest Points 2D
1 Learning Goals
- Analyze runtime of Divide and Conquer Algorithm [DC1]
- Create a Divide and Conquer Algorithm [DC1]
- Analyze ethics of an algorithm using the ethical matrix [Eth1]
- Prove Correctness of a Divide and Conquer Algorithm [DC3]
- Benchmark algorithm with brute force approach / easier problem
- Build intuition with easier problem
2 Introduction to the Closest Points Problem
2.1 Description
Input:
Assumption: No two points have the same \(x\) coordinate or the same \(y\) coordinate. For example, \((1,2)\) and \((1,4)\) would not be allowed.
Output: The distance between the two closest points in \(P\), where distance is calculated using the Euclidean distance: \[ d(p_1,p_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\]
Applications of closest points (usually variants of this algorithm):
- Robotics (find the closest points between robot and environment)
- Designing roofs
- Air traffic control (identify planes that are closest together and so most likely to have a collision)
The algorithm itself is essentially a mathematical object. But once it gets implemented for a particular task, it has ethical implications.
3 Designing an Algorithm for the Closest Points Problem
3.1 Targeting performance
Before designing a sophisticated algorithm, it is good to try to figure out what kind of performance (time complexity) we might like our algorithm to achieve. We can do this by analyzing simpler brute force approaches (worst-case) and analyzing algorithms for easier problems (best-case). We would like our sophisticated algorithm to be better than brute force, but we don’t expect it to do better than the best algorithm for an easier problem.
A Brute Force algorithm is one that does the simplest thing possible. In this case, that means checking every pair. Here is pseudocode that does this:
\(\texttt{BruteForceCloPts}(P)\)
- \(\min\gets \infty\)
- For \(i\gets 1\) to \(n-1\):
- \(\quad\) For \(i\gets i+1\) to \(n\):
- \(\qquad\) If \(dist(p_i,p_j)<\min\), then \(\min\gets dist(p_i,p_j)\)
- return \(\min\)
An easier problem than 2D Closest Points is 1D Closest Points. We would not expect a 2D algorithm to be faster than a 1D Algorithm. In 1D Closest points, your input is an array \(P\) of size \(n\) of unsorted numbers. For example, \(P=[5,9,0,20,17]\).
Introduce yourself!
We are going to be doing a lot of in-class group problem solving, and we’ll brainstorm solutions to the following common difficulties. For each difficulty, come up with at least 2 learning-centered approaches
- 0 mode 4 groups: one group member is really quiet and rarely says anything
- 1 mode 4 groups: your group mates are going in a direction you think is definitely not correct, and you are getting frustrated that you are not going to be able to finish and get the most out of the activity
- 2 mode 4 groups: when you suggest an approach, your group mates don’t seem to take it seriously
- 3 mode 4 groups: One group member loves to jump right in to solving, while another prefers to have time to process and think
Use pseudocode to describe a \(O(n\log n)\) non-recursive algorithm for 1D Closest Points that starts with the line \(\texttt{Sort}\).
[DC1] Analyze the runtime of the brute force approach and the non-recursive approach.
[DC2] Design a recursive algorithm for 1D Closest Points when input is an array \(P\) of size \(n\) of unsorted numbers. (Fill in the missing code.)
[DC1] Determine the runtime of your algorithm
Keep in mind some of the concepts from MergeSort: - Need to go to the base case when the input is too small to divide further - Need to think about how to solve the whole problem if can solve the parts
What size set of points should trigger the base case?
- \(0\)
- \(\leq 1\)
- \(\leq 2\)
- \(\leq 3\)
This brings us to a strategy to improve the runtime of a recursive algorithm:
- identify the slowest parts in the recursive call
- remove those parts from recursion and do ahead of time, or try to speed them up.
3.2 Ethical Implications
Before we get into the details of designing this algorithm, let’s first analyze whether implementing this algorithm for a particular purpose will be good, ethically.
As we mentioned previously, there are several applications for the closest points algorithm (usually variants of this algorithm):
- Robotics (find the closest points between robot and environment)
- Designing roofs
- Air traffic control (identify planes that are closest together and so most likely to have a collision)
We will be using a tool called the “Ethical Matrix” developed for algorithmic applications by O’Neil and Gunn.
To set up the matrix, you should create a table with the following columns: Stakeholders, Well-Being, Autonomy, and Justice:
- Stakeholders Each row should list a stakeholder: someone or something that is affected by the implementation of the algorithm in the specified scenario. It is important to try to think of as many stakeholders as possible - otherwise you will miss possible impacts of the algorithm.
- Well-Being In the Well-Being column, you should note what harms or benefits the stakeholder will likely derive from the algorithm.
- Autonomy In the Autonomy column, you should note whether the stakeholder has a choice in whether to use the algorithm (or have the algorithm be used on them). Also, you should note if the stakeholder is informed enough about the workings of the algorithm to responsibly use. (This last is more important for machine learning algorithms, which we will not be looking at much in this class, but can sometimes be important for simpler algorithms.)
- Justice In this column, you should think about whether there is unfair treatment of different groups, either within a stakeholder group, or across stakeholder groups.
For example, if we consider using the closest points algorithm to improve air traffic control, a row of the ethical matrix might look like:
| Stakeholders | Well-Being | Autonomy | Justice |
|---|---|---|---|
| Airplane passengers | Safety, Cheaper, Environment | Alternative transit, virtual options | Unequal access (rich/poor, geographic location) |
As a large group, we’ll brainstorm possible stakeholders.
Ice breaker: Where do you want to travel to, and why?
For the stakeholders we selected, fill out the rest of the ethical matrix.
Identify one concerning block, and think of a way to ameliorate, either by modifying the algorithm, or providing recourse to the affected party.
After filling in the ethical matrix, you can highlight blocks of the matrix as green (positive), white (not strongly positive or negative), yellow (some problem), and red (very problematic). This coloring can help highlight the potential advantages and disadvantages of using the algorithm.
Creating an ethical matrix does not tell you what to do. As with most ethical decisions, there is not always a clear answer. However, this tool helps you think about the consequences of implementing an algorithm, before actually implementing it. In particular you might consider:
- How can you mitigate negative consequences? Can you modify the algorithm to do so? Can you provide additional aid to those who might be negatively affected?
- If the effects are so negative, might you try to convince your bosses not to use this algorithm? Would you leave your company rather than work to implement an algorithm?
3.3 Sketching a Divide and Conquer Algorithm:
Here is a first pass at an algorithm up to the combine step:
\(\texttt{CloPts}(P)\)
Base case: If \(n\leq 3\), do a brute force search and return smallest distance found.
Divide: Let’s sort the points by \(x\)-coordinates, and then divide into a left and right half. For example, if we have 6 points sorted by \(x\)-coordinate: \[P=((1,5), (2,2),(4,4), (10,20), (12,3), (19,6)) \] then we’ll divide into a left half and right half \[L=((1,5), (2,2),(4,4))\] \[R=((10,20), (12,3), (19,6)).\] We’ll call \(7\) the midline, because \(7\) is midway between \(4\) and \(10\), the \(x\)-coordinates of the two points on either side of the divide. Note that \(7\) is not literally in the middle of the space of points. The \(x\)-coordinates of the points range from \(1\) to \(19\), so if we were to just divide that space, we might get a midline of \(10\), which would not correctly divide the points.
Conquer:
- \(\delta_1=\texttt{CloPts}(L)\)
- \(\delta_2=\texttt{CloPts}(R)\)
- \(\delta=min\{\delta_1,\delta_2\}\)
We will start the proof of correctness of the algorithm up to the combine step:
Proof. We will prove using strong induction that \(\texttt{CloPts}\) correctly returns the distance between the closest pair of points for all \(n\geq 2\), where \(n=|P|.\)
Base case: when \(n=2\) or \(n=3\), the base case of the algorithm correctly finds the smallest distance via brute force.
Inductive step: Let \(k\geq 3\), and assume \(\texttt{CloPts}\) is correct for all input sizes \(j\) for \(2\leq j\leq k\). Consider an input of size \(k+1\).
Since \(k+1\geq 4\), we skip the base case and go to the inductive setp. Further, since \(k+1\geq 4\), when we divide into left (\(L\)) and right (\(R\)) halves on either side of the midline, \(L\) and \(R\) each have at least \(2\) but less than \(4\) points in them, so by our inductive assumption, the recursive calls \(\texttt{CloPts}(L)\) and \(\texttt{CloPts}(R)\) each correctly return the closest distance among their respective points. Thus \(\delta\) contains the smallest distance between points where both points are to the left of the midline or both are to the right of the midline.
Next we need to find if there is a closer pair of points where one point is in \(L\) and one is in the \(R\).
(To be continued!)
3.4 The Combine Step
3.4.1 Region near the midline
Assuming the recursive calls work correctly, we will have found the distance between the closest pair of points both on the left of the midline, and the distance between the closest pair of points both on the right of the midline, so the only thing we need to worry about is if the closest pair of points in the whole set is a pair where one point is in \(L\) and one point is in \(R\), crossing the midline.
However, it seems like points that are very far away from the midline can be ignored. As shown in the picture, if we have already found a pair in \(R\) with distance \(1\), then a point in \(R\) that is \(10\) away from the midline can’t possibly be part of the closest pair with a point in \(L\).
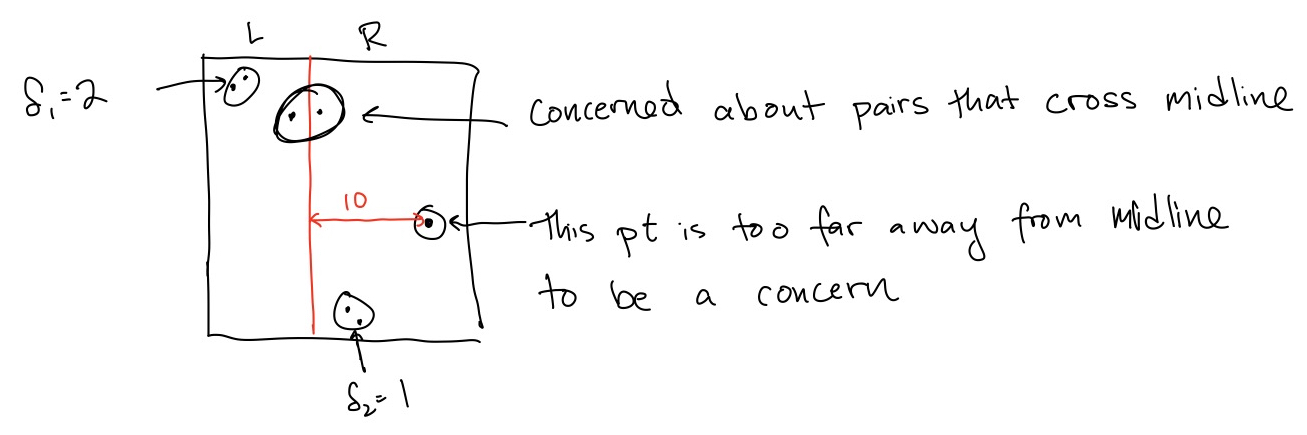
Recalling that \(d(p_1,p_2)=\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\), which points do we need to worry about in the combine step? Those within
- \(\delta/2\) of midline
- \(\sqrt{\delta}\) of midline
- \(\delta\) of midline
- \(2\delta\) of midline
Let’s continue the proof:
Proof. However, we only need concern ourselves with points whose \(x\)-coordinates are within \(\delta\) of the midline. To see this, consider a pair where \(p_1\) is in \(L\), and \(p_2\) is in \(R\) and more than \(\delta\) to the right of the midline. Then \[ x_1<midline, \quad x_2>midline+\delta. \tag{1}\]
Then the Euclidean distance between \(p_1\) and \(p_2\) is \[ \begin{align} d(p_1,p_2)=&\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}\\ \geq &\sqrt{(x_1-x_2)^2}\\ =&x_2-x_1\\ >&(midline+\delta)-midline\\ =&\delta \end{align} \] where the first inequality comes from removing the \((y_1-y_2)^2\), which is positive, and the last inequality comes from Equation 1.
Thus \(p_1\) and \(p_2\) have a distance larger than \(\delta\), and so can not be the closest pair. (A similar argument holds for points to the left of the midline.) Therefore, we need only consider points in \(Y_\delta\), the region within \(\delta\) of the midline, which we do in the code below
(Proof to be continued…)
Combine Step
\(Y_\delta\leftarrow y\)-sorted list of points in \(P\) within \(\delta\) of midline
3.4.2 Almost like 1-D
If you squint, the region close to the midline almost looks like points on a line, as in the picture
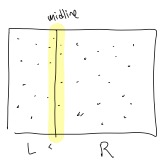
Why don’t we try using an approach similar to a line:
Combine Step
\(Y_\delta\leftarrow y\)-sorted list of points in \(P\) within \(\delta\) of midline
\(p\in Y_\delta\):
\(\quad\) Check distance from \(p\) to next ???? points
\(\quad\) Save if smallest distance found
While in our example of points on a 1-D line, we only needed to look at the next sorted point, in this case, looking at just the next point is not sufficient. To see this, consider the following picture:
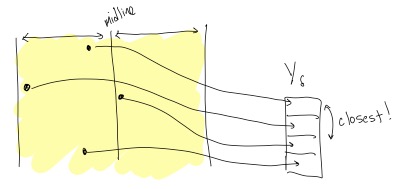
In this picture, the closest point to the top point is actually not the next point in \(Y_\delta\), but the one after that.
What should ??? be replaced by in the above code?
To solve this problem, show that you can’t cram too many points near \(p\) because the closest points both in \(L\) or both in \(R\) must have distance at least \(\delta\), and also \(Y_\delta\) only contains points within \(\delta\) of the midline.
We can now finish the proof:
Proof. (See post-class pdf at top of this page for picture and missing info in below proof)
Imagine dividing the region within \(\delta\) of midline into \(\delta/2\times\delta/2\) squares starting at the current point, which we call \(p\). Each of these squares can contain at most one point. To see this, for contradiction, suppose there are 2 points in a square. Then the difference in their \(x\)-coordinates is at most \(\delta/2\), and the difference in their \(y\)-coordinates is at most \(\delta/2\), so their distance is at most \[\sqrt{\left(\frac{\delta}{2}\right)^2+\left(\frac{\delta}{2}\right)^2}=\frac{\delta}{\sqrt{2}}.\] This is a contradiction, since every square contains only points in \(L\) or only points in \(R\), and we know that any two points that are both in \(L\) or both in \(R\) must have a distance of at least \(\delta\), since that is the smallest distance found in our recursive calls which we get to assume are correct.
Now if we consider rows of boxes below \(p\), since each row has height \(\delta/2\), any points that are in the \(3^\textrm{rd}\) row of boxes will have a difference in \(y\)-coordinate from \(p\) that is at least \(\delta\). This means it will have a distance from \(p\) that is at least \(\delta\), and so we need not check any points in rows 3 or more below \(p\).
Thus there are only xxxx relevant boxes, and \(p\) is in one box, so there are at most ??? boxes that might contain the next closest point to \(p\), and each of these boxes contains at most one point, and all of these points would appear immediately after \(p\) in \(Y_\delta\) since \(Y_\delta\) is sorted by \(y\)-coordinate.
\(\square\)
3.5 Algorithm
Finally, we can write down the full pseudocode for the algorithm. (See post-class pdf at top of page for missing values.)
CloPts(P)
// Base Case
If \(|P|\leq ...\), then do brute force//Divide
Sort \(P\) by \(x\)-coordinate, and then divide into arrays \(L\) and \(R\)
Pick midline to be midway between \(L\) and \(R\)// Conquer
\(\delta=min\{\texttt{CloPts}(L),\texttt{CloPts}(R)\}\)// Combine
$Y_$ pts within *** of midline, sorted by \(y\)-coordinate
\(\texttt{for}\) \(p_i\in Y_\delta\):
\(\quad\) \(\texttt{for}\) \(j\leftarrow i+1\) to \(i+???\):
\(\qquad\) if \(d(p_i,p_j)\leq \delta\), then \(\delta\leftarrow d(p_i,p_j)\)
return \(\delta\)
Try to explain in your own words why this is correct? What questions do you have about why this algorithm works?
4 Runtime
In groups, create a recurrence relation for the runtime of the Closest Points algorithm, using the pseudocode above.
It turns out the approach described above is not optimal. We are repeatedly sorting by \(x\) and \(y\) at each recursive step, and this adds extra factors to the runtime. Instead, we’ll presort the points before running the recursive algorithm:
** PreSort(P)
\(X\leftarrow P\) sorted by \(x\)
\(Y\leftarrow P\) sorted by \(y\)
return \(X,Y\)
CloPts(X, Y)
// Note that \(X\) and \(Y\) should contain the same set of points, just one array is sorted by \(x\) and one by \(y\).// Base Case
1. If \(|P|\leq ...\), then do brute force//Divide
2. Divide \(X, Y\) into \(X_L,X_R,Y_L, Y_R\), and pick midline// Conquer
3. \(\delta=min\{\texttt{CloPts}(X_L,Y_L),\texttt{CloPts}(X_R,Y_R)\}\)// Combine
4. Create \(Y_\delta\) from \(Y\) and midline
5. \(\texttt{for}\) \(p_i\in Y_\delta\):
\(\quad\) \(\texttt{for}\) \(j\leftarrow i+1\) to \(i+???\):
\(\qquad\) if \(d(p_i,p_j)\leq \delta\), then \(\delta\leftarrow d(p_i,p_j)\)
6. return \(\delta\)
We will go through and analyze the runtime of each step.
- \(O(1)\)
- This step can be done in \(O(n)\) time. \(X\) can be split by doing a loop through the elements and copying the first half in-order into \(X_L\) and copying the second half in-order into \(X_R\). \(Y\) can be split by doing a loop through the elements of \(Y\) and checking the \(x\)-coordinate of each point, and if the \(x\)-coordinate of the point is less than the midline value, copy it to the next empty spot in \(Y_L\), and if the \(x\)-coordinate of the point is more than the midline value, copy it to the next empty spot in \(Y_R\). Each of these loops only goes through \(X\) or \(Y\) one time and does constant work within each loop, so the runtime is \(O(n)\).
- \(2T(n/2)+O(1)\), for the two recursive calls, each on an input half the size of the original, plus constant time to take the minimum
- We again loop through \(Y\), and check the \(x\)-coordinate of each point, and if the \(x\)-coordinate of the point within \(\delta\) of the midline, we copy it \(Y_\delta\), and otherwise we do nothing with the point and just continue to the next for loop iteration.
- Since \(Y_\delta\) can have at most \(n\) points in it, the outer loop will run at most \(n\) times. The inner for loop only iterates a constant number of times, and then the if statement only takes a constant amount of time, so the entire process takes \(O(n)\) time.
- O(1)
Combining the contributions of each step and using big-O rules for adding runtimes, we get that the runtime is \[T(n)= \begin{cases} O(1), \textrm{ if }n\leq ...\\ 2T(n/2)+O(n), \textrm{ else} \end{cases}\] We can use the tree formula for this recurrence relation, and we find that the runtime is \(O(n\log n)\)!! This means we have achieved the same runtime as for 1-D, the best we could have possibly hoped for. Wow!
Where did we need the assumption that \(x\), \(y\) points are unique?